충돌형 리브
매트 플롯 리브(Matplotlib)은 파이썬에서 자료를 차트(chart)와 플롯(plot)에서 시각화하는 패키지이다. 매트 플롯 리브는 다음과 같은 정형화된 차트와 플롯 외에도 저 수준 API을 사용한 다양한 시각화 기능을 제공한다.라인 플롯(line plot), 스캬쯔타ー 플롯(scatter plot), 바 차트(bar chart), 히스토그램(histogram), 박스 플롯(box plot)등 다양한 차트 종류를 시각화할 수 있다. 이러한 정형화된 차트와 플롯의 외에도 API을 사용한 시각화에 활용할 수 있다.
matplotlib 임포트 하다
numpyasnpimportpandaaspdimportmatplotlibasmplimpimportmatplotpyplotaspltimportwarnings警告です。필터경고(“)
matplotlib는 원래 한글 지원이 안된다고 한다. 시각화 전에 아래 코드를 실행시켜 한글이 깨지지 않도록 해준다.

#importmatplotlibmatplotlib.rcParams[‘axes]. unicode_import’]=False#”matplotlibimportfont_manager, rcplt.rcParams[‘axes]에서 플랫폼을 가져옵니다.unicode_fonts’]=Falseifplatform.system”==’Darwin’:rc(‘font’, family=’AppleGothic’)elifplatform.system”==’Windows’:path=”c:/Windows/Fonts/malgun.ttf”font_name=font_manager.FontProperties(fname=path). get_name(‘rc’), family=family_name)else:print(‘불분명한 시스템…미안~~’)

# importmatplotlibmatplotlib.rcParams [‘axes].unicode_import’] = False #”matplotlibimportfont_manager, rcplt.rcParams [‘axes]에서 플랫폼을 가져옵니다.unicode_fonts’]=Falseifplatform.system”==’Darwin’:rc(‘font’,family=’AppleGothic’)elifplatform.system”==’Windows’:path=”c:/Windows/Fonts/malgun.ttf”font_name=font_manager.FontProperties(fname=path)。get_name(‘rc’),family=family_name)else:print(‘不明なシステム… ごめん~~~~~~~~~~´)

# importmatplotlibmatplotlib.rcParams [‘axes].unicode_import’] = False #”matplotlibimportfont_manager, rcplt.rcParams [‘axes]에서 플랫폼을 가져옵니다.unicode_fonts’]=Falseifplatform.system”==’Darwin’:rc(‘font’,family=’AppleGothic’)elifplatform.system”==’Windows’:path=”c:/Windows/Fonts/malgun.ttf”font_name=font_manager.FontProperties(fname=path)。get_name(‘rc’),family=family_name)else:print(‘不明なシステム… ごめん~~~~~~~~~~´)

기본적인 그리는 방법은 생략

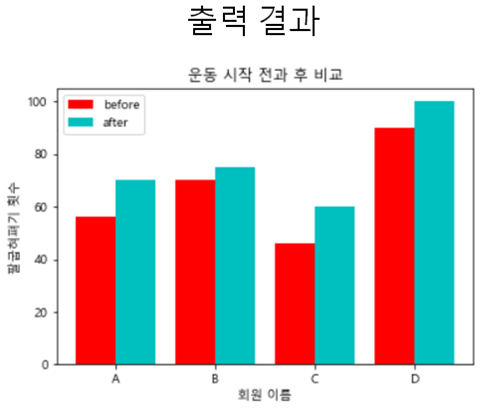
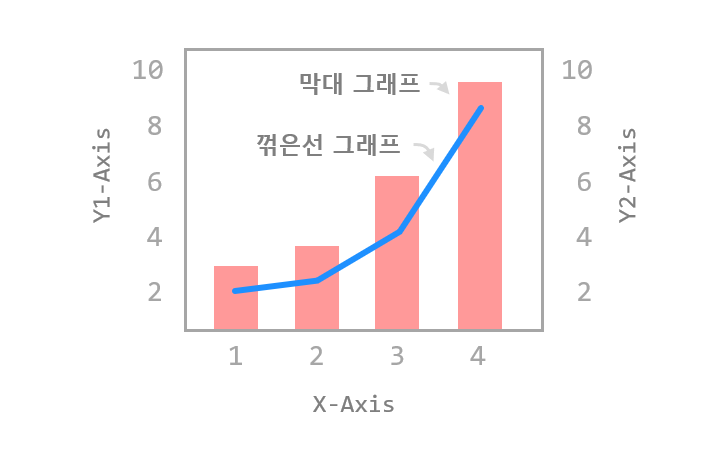
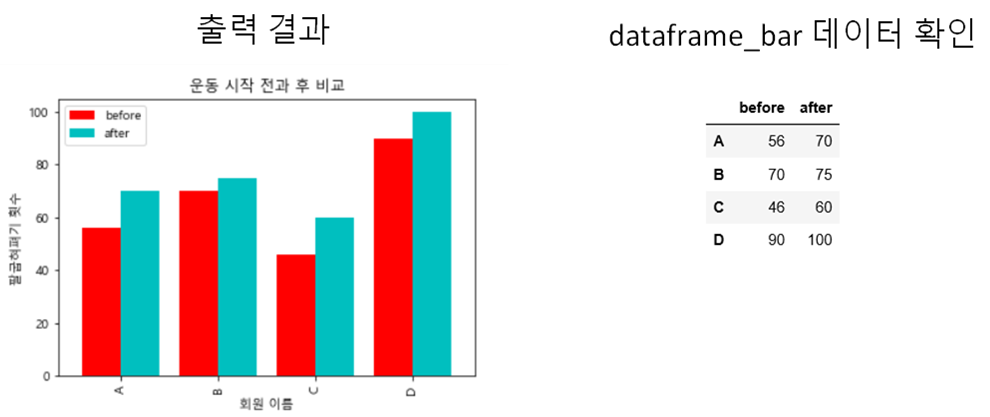
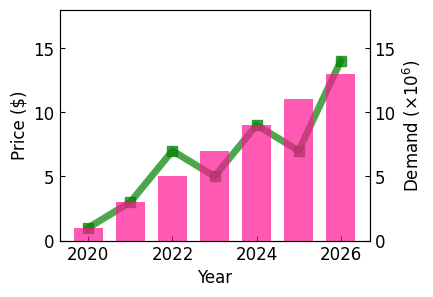
#옵션 추가보기 plt.figure() plt.title(‘라인플롯’) #plt.plot([1,2,3,4,5,6,7]) #y축 없이도 그릴 수 있는 plt.plot([10,30,60,95],[1,4,9,16], #x축,y축을 행과 열로 하자 c=’red’, #라인의 컬러 lw =3, #라인굵기 ls =’,마커’mark’) 3,4,12,13, ##옵션 추가보기 plt.figure() plt.title(‘라인플롯’) #plt.plot([1,2,3,4,5,6,7]) #y축 없이도 그릴 수 있는 plt.plot([10,30,60,95],[1,4,9,16], #x축,y축을 행과 열로 하자 c=’red’, #라인의 컬러 lw =3, #라인굵기 ls =’,마커’mark’) 3,4,12,13, #[연습1]시도별 전출입인구수.xlsx파일을 활용하여 연습tmp_frm = pd.read_excel(‘./data/시도별 전출입 인구수.xlsx’) tmp_frm.fillna(method = ‘ffill’, axis = 0, inplace = True) #1열이 무의미하므로 .fillna() 처리해준다.tmp_frm.head()tmp_frm = pd.read_excel(‘./data/시도별 전출입 인구수.xlsx’) tmp_frm.fillna(method = ‘ffill’, axis = 0, inplace = True) #1열이 무의미하므로 .fillna() 처리해준다.tmp_frm.head()#전송처리#서울에서 타지역으로 이동한 데이터만을 추출하여 서브셋 작성#(전송지=서울,전송지별 컬럼 삭제,이동자 여러줄 삭제) seoul_frm = tmp_frm [(tmp_frm[‘전출지별’] == “서울특별시’) & (tmp_frm[‘전입지별’] ! = “서울특별시’)” seoul_frm.head()#전송처리#서울에서 타지역으로 이동한 데이터만을 추출하여 서브셋 작성#(전송지=서울,전송지별 컬럼 삭제,이동자 여러줄 삭제) seoul_frm = tmp_frm [(tmp_frm[‘전출지별’] == “서울특별시’) & (tmp_frm[‘전입지별’] ! = “서울특별시’)” seoul_frm.head()# 불필요한 행 삭제 및 컬럼명 변경 seoul_frm.drop(‘전출지별’, axis=1,inplace=True) seoul_frm.rename({‘전입지별’:’전입지’}, axis=1,inplace=True) seoul_frm.set_index(‘전입지’, inplace=True) seoul_frm.head(‘)# 불필요한 행 삭제 및 컬럼명 변경 seoul_frm.drop(‘전출지별’, axis=1,inplace=True) seoul_frm.rename({‘전입지별’:’전입지’}, axis=1,inplace=True) seoul_frm.set_index(‘전입지’, inplace=True) seoul_frm.head(‘)1-1) 년별로 서울에서 경기도로 전입한 인구를 시각화해 보시기 바랍니다.#경기도전입인구 데이터만 추출 : 전입지=경기도 #gyenggi_frm=seoul_frm([‘전입지’]=’경기도’) data_series=seoul_frm.loc [‘경기도’] data_series.head()#경기도전입인구 데이터만 추출 : 전입지=경기도 #gyenggi_frm=seoul_frm([‘전입지’]=’경기도’) data_series=seoul_frm.loc [‘경기도’] data_series.head()print(“경기도로 이동한 인구 데이터를 이용한 시각화”) plt.figure(figsize=(15,5)) #그래프 사이즈 설정 plt.plot(data_series.index, data_series.values, c=’blue’, #라인 컬러 lw=2, #라인 굵기 ls=’-‘-‘, #라인 종류 marker=’o’, #마커사이즈) plt.show() plt.close()print(“경기도로 이동한 인구 데이터를 이용한 시각화”) plt.figure(figsize=(15,5)) #그래프 사이즈 설정 plt.plot(data_series.index, data_series.values, c=’blue’, #라인 컬러 lw=2, #라인 굵기 ls=’-‘-‘, #라인 종류 marker=’o’, #마커사이즈) plt.show() plt.close()1-2) 충청남도, 경상북도, 전라남도로 이동한 인구 데이터를 시각화해 보십시오.print(“충남, 경북, 전남으로 이동한 인구 데이터를 시각화”)#데이터를 별도로 추출하고 그리지 않고 plt.plot내에서 칼럼과 행을 지정하는 방법 plt.figure(figsize=(15,5)#그래프 사이즈 설정 plt.plot(seoul_frm.columns.values, seoul_frm.loc[충북], lw=2, marker=”*”, ms=5, msolum.plotolum.plolum.plolum.plolumrm.columns.values, seoul_frm.loc[‘전라남도’], lw=2, marker=’*’, ms=5)plt.xlabel(‘년도’)plt.ylabel(‘이동 인구 수’)plt.xticks(rotation=50)#x축 표시 간격이 좁은 겹치므로 각도를 조정하는 옵션 plt.show()plt.close()print(“충남, 경상북도, 전라남도로 이동한 인구 데이터 시각화”) # 데이터를 따로 추출하여 그리지 않고 plt.plot 내에서 컬럼과 행을 지정하는 방법 plt.figure(figsize=(15,5)) #그래프 크기 설정 plt.plot(seoul_frm.columns.values,seoul_frm.loc[충북], lw=2,marker=”*”,ms=5,msolum.plotolum.plolum.plolumns.values,seoul_frm.loc[‘전라남도’],lw=2,marker=’*’,ms=5)plt.xlabel(‘연도’) plt.ylabel(‘이동인구수’) plt.xticks(rotation=50) #x축 표시 간격이 좁게 겹치므로 각도를 조정한다.1-3) subplot 활용해보기print(‘subplot 방법’)fig = plt.figure(figsize = (20,7))area01 = fig.add_subplot(1,3,1)area01.plot(seoul_frm.columns.values , seoul_frm.loc[‘충청남도’].values , marker = ‘+’ , ms=5 , label=’충청남도’)area01.set_title(‘충청남도’)area01.set_xlabel(‘년도’)area01.set_ylabel(‘이동 인구수’)area01.set_xticklabels(labels = seoul_frm.columns.values , rotation = 90)area01.set_ylim(5000, 60000)area01.legend(loc=’best’)area02 = fig.add_subplot(1,3,2)area03 = fig.add_subplot(1,3,3)area02.plot(seoul_frm.columns.values , seoul_frm.loc[‘경상북도’].values , marker = ‘+’ , ms=5 , label=’경상북도’)area03.plot(seoul_frm.columns.values , seoul_frm.loc[‘전라남도’].values , marker = ‘+’ , ms=5 , label=’전라남도’)plt.show()plt.close()print(‘subplot 방법’)fig = plt.figure(figsize = (20,7))area01 = fig.add_subplot(1,3,1)area01.plot(seoul_frm.columns.values , seoul_frm.loc[‘충청남도’].values , marker = ‘+’ , ms=5 , label=’충청남도’)area01.set_title(‘충청남도’)area01.set_xlabel(‘년도’)area01.set_ylabel(‘이동 인구수’)area01.set_xticklabels(labels = seoul_frm.columns.values , rotation = 90)area01.set_ylim(5000, 60000)area01.legend(loc=’best’)area02 = fig.add_subplot(1,3,2)area03 = fig.add_subplot(1,3,3)area02.plot(seoul_frm.columns.values , seoul_frm.loc[‘경상북도’].values , marker = ‘+’ , ms=5 , label=’경상북도’)area03.plot(seoul_frm.columns.values , seoul_frm.loc[‘전라남도’].values , marker = ‘+’ , ms=5 , label=’전라남도’)plt.show()plt.close()1~4)년도에 따른 지역별 인구전입수를 바그래프로 시각화하라print(‘step 1) 2010~2017년도 충청남도,경상북도,강원도,전남 subset 만들기’) subset_frm = seoul_frm.loc[[‘충남’,’경상북도’,’강원도’,’전라남도’,’2010′:’2017′] subset_frmprint(‘step 1) 2010~2017년도 충청남도,경상북도,강원도,전남 subset 만들기’) subset_frm = seoul_frm.loc[[‘충남’,’경상북도’,’강원도’,’전라남도’,’2010′:’2017′] subset_frmprint(‘step 1) 2010~2017년도 충청남도,경상북도,강원도,전남 subset 만들기’) subset_frm = seoul_frm.loc[[‘충남’,’경상북도’,’강원도’,’전라남도’,’2010′:’2017′] subset_frmprint(‘step 2) x축 y축 트랜스포즈로 전환 후 Bar시각화 함) t_subset_frm=subset_frm.transpose() plt.figure() t_subset_frm.plot(kind=’bar’, figsize=(15,5)) plt.title(‘연도에 따른 권역별 전입인구수’) plt.xlabel(‘전입인구수’ticks) 0)print(‘step 2) x축 y축 트랜스포즈로 전환 후 Bar시각화 함) t_subset_frm=subset_frm.transpose() plt.figure() t_subset_frm.plot(kind=’bar’, figsize=(15,5)) plt.title(‘연도에 따른 권역별 전입인구수’) plt.xlabel(‘전입인구수’ticks) 0)1-5) 여기에 권역별 합계를 추가하고 내림차순 정렬을 하여 가장 많은 값을 가진 권역을 정렬 수평봉 그래프로 그려보자(문제를 일단 이해할 수 없음).# 여기에 권역별 합계를 추가하여 내림차순 정렬을 해보자 subset_frm[‘합계’] = subset_frm.sum(axis = 1)sum_subset_frm = subset_frm.sort_values(‘합계’,ascending = False)# 여기에 권역별 합계를 추가하여 내림차순 정렬을 해보자 subset_frm[‘합계’] = subset_frm.sum(axis = 1)sum_subset_frm = subset_frm.sort_values(‘합계’,ascending = False)# 다음으로 권역별 합계가 가장 많은 권역값을 막대그래프로 시각화해 보자 plt.figure(figsize=(15,5)) plt.bar(#sum_subset_frm.index, [‘충청’, ‘강원’, ‘경상’, ‘전라’], sum_subset_frm[‘합계’].values, label=’라벨명’) plt.ylabel(‘권역’) plt.ylabel(‘tectles) plt.# 다음으로 권역별 합계가 가장 많은 권역값을 막대그래프로 시각화해 보자 plt.figure(figsize=(15,5)) plt.bar(#sum_subset_frm.index, [‘충청’, ‘강원’, ‘경상’, ‘전라’], sum_subset_frm[‘합계’].values, label=’라벨명’) plt.ylabel(‘권역’) plt.ylabel(‘tectles) plt.[연습2] 타이타닉 데이터를 이용하여 선실별 생존자 합계와 선실 등급에 따른 생존자 시각화를 해보자.snsiris_frm=sns.load_(‘iris’iris’)_load_frm=sns.load_titanic’)#importsnsseab)#별자생존 group;:groupby, 등급에생따 bar존자른 plot:barplot(x범주형인경우축'(‘):xtitanic용 indexclass)사 printprint지수:’, titanic_frm.grambybypclass’)survived.sum(). index)print(값:’, titanic_frm.groupby(pclass’). survived.sum(). values)plt.figure(figsize=(15,5)plt.bar(titanic_frm.groupby”pclass’). survived.sum(). index, titanic_frm.groupby(pclass’). survived.sum(). values, label=’존자등)”)plt.xlabel(p실자급’)”)plt.xticks(titanic_frm.groupbyclasspclass’). survived.sum(. index)plt.close(loc=’best’)plt.show”plt.close”snsiris_frm=sns.load_(‘iris’iris’)_load_frm=sns.load_titanic’)#importsnsseab)#별자생존group:::groupby,등급에생따bar존자른plot:barplot(x범주형인경우축'(‘):xtitanic용indexclass)사printprintインデックス:’,titanic_frm.grambybypclass’)survived.sum().index)print(値:’,titanic_frm.groupby(pclass’)).survived.sum().values)plt.figure(figsize=(15,5))plt.bar(titanic_frm.groupby”pclass’)。survived.sum().index、titanic_frm.groupby(pclass’)。survived.sum().values,label=’존자등)”)plt.xlabel(p실자급’)”)plt.xticks(titanic_frm.groupbyclasspclass’).survived.sum(.index)plt.close(loc=’best’)plt.show”plt.close”[연습3] iris 데이터에서 종을 기준으로 그룹화한 후 각 그룹의 평균을 시각화해보자. (조건: 컬럼 이름을 한글로 변경)iris_frm.rename(columns = {‘sepal_length] : ‘꽃잎의 길이’, ‘sepal_width’ : ‘꽃잎의 길이’, ‘petal_width’ : ‘꽃잎의 폭’}, inplace = True)iris_frmiris_frm.rename(columns = {‘sepal_length] : ‘꽃잎의 길이’, ‘sepal_width’ : ‘꽃잎의 길이’, ‘petal_width’ : ‘꽃잎의 폭’}, inplace = True)iris_frm내가 그렇게 한 방법plt.figure(figsize=(15,5)plt.plot(speces_grp.example.values, speces_grp.loc[‘setosa’], lw=3, ms=10)plt.plot(speces_grp.example.values, speces_grp.example.exames, ms=10)plot(speces_grp.example.exames.example.values, spec.ex lw=3, 마커=’*’, ms=10)plt.xlabel(“”””)plt.ylabel(“”””””)plt.show(plt.close)plt.figure(figsize=(15,5))plt.plot(speces_grp.example.values,speces_grp.loc[‘setosa’],lw=3,ms=10)plt.plot(speces_grp.example.values,speces_grp.example.exames,ms=10)plot(speces_grp.example.exames.example.values,spec.ex lw=3、マーカー=’*’,ms=10)plt.xlabel(“”””)plt.ylabel(“”””””)plt.show(plt.close)그리고 그대로의 결과.결과는 아래와 같이 나와야 한다(다시..해본다.)kind=”box”로 주면 양적 자료의 데이터 분포를 확인할 수 있는 박스플롯을 그릴 수 있다.kind = bar 로 주면 이상해kind = bar 로 주면 이상해